Benchmark — Prove it holds up
Benchmark
The Benchmark proves which agent and model actually hold up on the work your teams really do, on your own hardware, before you commit. It evaluates complete agent systems, not individual models in isolation.
Flexible by design
Benchmark on your terms
Choose where the Benchmark runs and which codebase it runs against — two decisions, four ways to turn questions about AI into evidence.
Where it runs
Evaluate before you invest
Test candidate models against your own business domain in the cloud — see which ones deliver, what hardware each would require, and whether a sovereign on-premises deployment is a credible alternative. Measure your real challenges before committing budget.
Optimise your own setup
Keep your AI stack at peak performance on your own infrastructure. When a new model is released, decide with evidence: does it run efficiently on your hardware, and can it handle your business challenges — before you switch?
What you benchmark on
Greenfield & shared challenges
Benchmark against greenfield challenges defined in a public pool, and gain insight from benchmarks shared by other users. As the same challenges are replayed over time, you also see how models' performance shifts — for instance when a cloud provider's update quietly changes results on the tasks you depend on.
Real problems, real projects
Find out whether an agent can truly handle the problems your engineering teams face. Run the Benchmark against your own repositories, entirely within your environment — on-premises or in your own cloud tenant — to measure real performance on real projects. Generic tests only go so far; benchmarking on your real projects gives far more insight.
Capabilities
Built for an honest decision
Agent + model + hardware
Every run pairs a coding agent with a model, because the system as a whole is what matters, not the model alone.
Hard metrics vs. judgement
Mechanical checks (build, tests, static analysis, security scans) are kept separate from LLM-as-a-judge review, never blended into one misleading number.
Scenario tiers
Run the same use case at rising levels of difficulty and abstraction, to see where a model starts to struggle.
Help tiers
Run a model with no, some, or maximum context. The spread shows how much hand-holding it needs, which explains why a model suits one team and not another.
Your own tasks, kept private
Bring your own repositories and coding challenges. Testing on your private stack sidesteps the contamination of public leaderboards.
Reproducible & versioned
Pinned commits and a saved configuration snapshot make every run reproducible, so you can re-test on each new model release.
Read-only and write channels
Observe shared GPUs without disturbing them, or deploy a model to local or cloud compute just for a run.
Leaderboard & trends
Compare models and agents side by side and track how they change over time, with results you can automate via an agent interface.
What it measures
What we capture
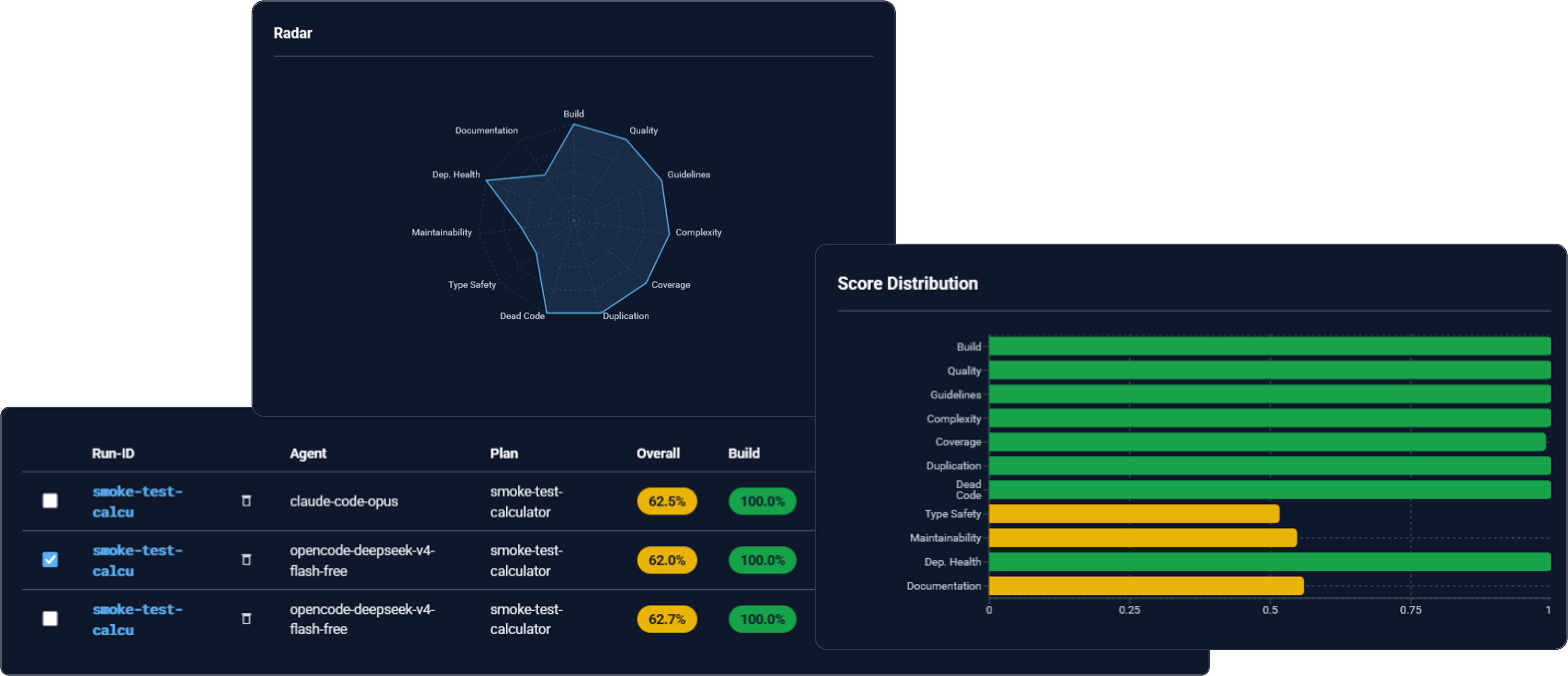
Every agent run is examined across three score axes — hardware, build and task — so a result is far more than just "did it run". What you see here is only a selection; each axis carries many more signals.
Hardware scores
Tokens/min, latency, runtime …
Build scores
Type safety, dead code, duplication …
Task scores
Requirement coverage, tests, pass@k …
Agent, model, hardware, task
Step 1
Pick generic tasks, or representative coding tasks from an internal software development project.
Step 2
Pick from a collection of models that run on your own infrastructure or in the cloud of your choosing.
Step 3
Run agents in isolated workspaces.
Step 4
Score with state-of-the-art metrics to compare model performance and cost on the given tasks.
Step 5
Compare results across models, over time.
You don't need a blast furnace to make toast.
Prof. Dr. Maja Göpel FSAS Technology Summit 2026
Not every task needs the biggest, most expensive model. Often a smaller, leaner one handles your concrete challenges just as well — and saves cost and resources along the way.
Decision support
Questions it helps you answer
A few of the calls teams make with it — alongside many more that are specific to your own domain.
Which model is worth hosting on your own infrastructure.
Weigh hosting cost against the quality you actually get.
How a model handles your own coding challenges before you commit.
Test on your real repositories, not a public leaderboard.
Why a model works for one team but not for another.
See how much context and hand-holding each team needs.
Whether a new release is actually better, tested the same way each time.
Re-run the identical, pinned benchmark on every release.
When a model is ready to promote into the Workbench.
Move it from evaluation to production once it clears your bar.
…and the questions that matter most to your own teams.
Bring your own criteria — the benchmark adapts to them.
